 I was enrolled in a research methods class at Duke with
Alison Koenka this summer and learned so much about measurement, validity,
reliability, and the different between-group and within-group research designs
commonly used in psychology and neuroscience. Thus, I feel very comfortable
with experiments. However, despite having taken a statistics course already at
Duke, I am still confused by statistical methods and find it difficult to make
sense of them. At a basic level, I understand that there are descriptive and
inferential statistics, and both are necessary for helping researchers
organize, summarize, and interpret the data in a way that some sense can be
made from it. I also remember the theory behind null hypotheses testing and do
find the alpha significance level of a comparison distribution to be important
in separating research that reports true effects in a population from research
that does not. However, though I am familiar with the normal distribution depicted below, I find myself lost in the details, especially with
regard to the statistical theory behind the F and t distributions. In addition,
while I do know about type I and type II errors, I do not understand what ‘power’
is and how some evidence has greater power than others.
I was enrolled in a research methods class at Duke with
Alison Koenka this summer and learned so much about measurement, validity,
reliability, and the different between-group and within-group research designs
commonly used in psychology and neuroscience. Thus, I feel very comfortable
with experiments. However, despite having taken a statistics course already at
Duke, I am still confused by statistical methods and find it difficult to make
sense of them. At a basic level, I understand that there are descriptive and
inferential statistics, and both are necessary for helping researchers
organize, summarize, and interpret the data in a way that some sense can be
made from it. I also remember the theory behind null hypotheses testing and do
find the alpha significance level of a comparison distribution to be important
in separating research that reports true effects in a population from research
that does not. However, though I am familiar with the normal distribution depicted below, I find myself lost in the details, especially with
regard to the statistical theory behind the F and t distributions. In addition,
while I do know about type I and type II errors, I do not understand what ‘power’
is and how some evidence has greater power than others. 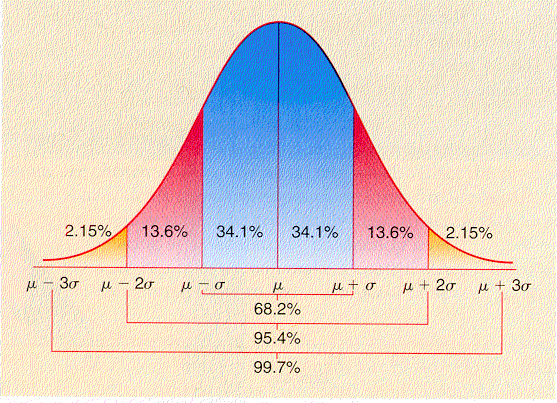
{kind=link}
Despite
my previous knowledge of research design and statistics, I still find
journal
articles confusing as well. Many times, articles use methods with which I
am
not familiar. For this reason, I am confused by the graphs and tables
provided
describing the experiment’s data. For example, I still do not understand
representations indicating EEG or TMS data. However, it is my hope that greater exposure to methods used by researchers in psychology and neuroscience will help me understand these graphs and images better.
No comments:
Post a Comment